엘라스틱 서치 설치하고 실행하기
설치는 mac환경에서 진행했습니다.
Elasticsearch 7.0 버전 부터는 기본 배포판에 open-jdk 가 포함되어 있어 따로 Java를 설치 해 주지 않아도 됩니다. 대신 운영체제에 맞게 배포판을 받아야 합니다.
Elasticsearch는 홈페이지 (https://www.elastic.co)의 Product 또는 다운로드 메뉴를 통해 다운로드를 할 수 있습니다. ZIP, TAR, DEB, RPM 등의 다운로드 파일과 yum, apt-get 등의 설치에 대한 메뉴얼이 있습니다.
ZIP 또는 TAR 파일을 내려받아 압축을 풀고, 생성된 bin 디렉토리 아래에 있는 elasticsearch (Windowns의 경우 elasticsearch.bat) 파일을 실행합니다. 데비안이나 레드햇 리눅스 시스템의 경우 DEB, RPM 파일을 내려받아 백그라운드 서비스로 실행도 가능합니다.
생성된 bin 디렉토리 아래에 있는 elasticsearch을 실행한 후, 해당 서버의 이름으로 엘라스틱 서치의 노드가 실행된 것을 확인할 수 있었습니다. 노드 이름은 직접 지정이 가능하며 지정하지 않았다면 7.0 버전 부터는 호스트명으로 생성되고 5.x, 6.x 버전에서는 노드 프로세스의 UUID의 첫 7자 알파벳으로 지정됩니다.
$ bin/elasticsearch -d
-d 옵션 : 백그라운드에서 실행
-d 옵션을 추가해서 Elasticsearch를 실행해보면 화면에 아무런 반응 없이 명령 수행이 끝나게 되고, 실행 중인 Elasticsearch의 실행 로그는 logs 디렉토리 아래에 <클러스터명>.log 파일에서 확인이 가능합니다. 아무런 설정을 하지 않았다면 기본적으로 logs/elasticsearch.log 에 저장됩니다.
$ ps -ef | grep elasticsearch
위 명령을 통해 엘라스틱서치의 프로세스 아이디를 얻을 수 있습니다. 백그라운드로 실행 중인 Elasticsearch 프로세스를 종료하려면 kill 명령을 사용해야 합니다.
-p 옵션 : 프로세스 ID를 파일로 저장
-p <파일명> 옵션을 추가해 실행된 Elasticsearch 프로세스 ID를 특정 파일에 저장할 수 있습니다.
$ bin/elasticsearch -d -p es.pid
위 명령어를 실행하면 엘라스틱 서치를 백그라운드 실행하면서 실행된 엘라스틱서치의 프로세스 아이디를 es.pid 파일에 저장할 수 있습니다.
$ echo 'bin/elasticsearch -d -p es.pid' > start.sh
$ echo 'kill `cat es.pid`' > stop.sh
$ chmod 755 start.sh stop.sh
# 엘라스틱 서치 실행
$ ./start.sh
# 엘라스틱 서치 종료
$ ./stop.sh
http://localhost:9200 을 기준으로 엘라스틱 서치가 구동됩니다. 포트를 배정받는 원리는 이 문서를 참고하시길 바랍니다.
키바나 설치하고 엘라스틱 서치와 연동하기
키바나(Kibana)
키바나(Kibana)는 ELK(Elasticsearch, Logstash, Kibana)라는 엘라스틱서치 스택의 주요 솔루션 중 하나로 엘라스틱서치와 연계를 이루면서 비주얼라이징(Visualizing)을 통한 유저 인터페이스(User Interface, UI)를 제공하는 솔루션입니다.
키바나를 설치하면 엘라스틱서치의 데이터를 쉽게 확인할 수 있고, 비주얼라이징을 통한 데이터 분석도 할 수 있으며, 관리기 역할까지 수행할 수 있습니다.
https://www.elastic.co/downloads/kibana 사이트로 이동하여, OS에 맡는 파일을 다운로드하면 키바나를 설치할 수 있습니다.
연동하기
키바나를 실행하기전 서버에서 엘라스틱 서치를 실행시킵니다.
이후 엘라스틱 서치와 같이 키바나의 bin 폴더로 들어가서 kibana 파일을 실행합니다.
키바나를 실행하면 콘솔창이 뜨면서 구동이 되는 것을 확인할 수 있습니다. 키바나를 구동하기 전에 엘라스틱 서치를 띄웠다면 엘라스틱 서치의 콘솔에도 키바나가 구동되며 연동된 것을 확인할 수 있습니다.
http://localhost:5601 을 실행하면, 키바나 화면을 보실 수 있습니다.
엘라스틱 서치 사용하기 위한 인덱스 구축
한글 형태소 분석기 nori 설치
한글 형태소 분석을 위한 nori라는 elastic search의 플러그인을 설치해줍니다. 설치를 실행해주는 파일은 엘라스틱 서치가 설치된 폴더의 bin 디렉터리 밑에 elasticsearch-plugin 파일입니다. 설치 명령어는 bin\elasticsearch-plugin install analysis-nori 입니다.
python elasticsearch & django환경 구성
새 폴더를 만들고 만들어준 폴더 안에서 가상환경을 생성한 후 활성화합니다.
python -m venv myvenv
myvenv\Scripts\activate
pip를 사용해서 django와 django restframework를 설치합니다.
pip install django
pip install djangorestframework
pip install elasticsearch==(version) 로 python에서 elasticsearch를 컨트롤하기 위한 모듈을 설치합니다.
pip install elasticsearch
pip list로 원하는 버전의 elasticsearch가 설치됐는지 확인합니다.
프로젝트를 만들고 프로젝트 내부에 별도의 어플리케이션을 만들어 줍니다.
django-admin.py startproject server_project
cd server_project
python manage.py startapp search_app
INSTALLED_APPS에는 현재 Django 인스턴스에 활성화된 모든 Django 애플리케이션의 이름들이 나열되어 있습니다. 애플리케이션은 다수의 프로젝트에서 사용할 수 있으므로 server_project/settings.py에서 등록을 해야 합니다. Django REST framework를 사용하기 위해 INSTALLED_APPS에 ‘rest_framework’를 추가해줍니다. 위에서 만들었던 ‘search_app’도 추가해줍니다.
# server_project/settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'search_app',
]
생성된 인덱스와 데이터를 이용해 bulk로 한번에 POST 하기
인덱스 설정 및 생성
한국어 검색에 적합한 인덱스를 생성하기 위해 한글 형태소 분석기 nori를 통해 데이터를 토크나이징할 수 있도록 설정합니다. search_app 디렉터리에 setting_bulk.py 파일을 생성해서 따로 구현해주었습니다.
# search_app/setting_bulk.py
import requests, json, os
from elasticsearch import Elasticsearch
directory_path = 'path'
res = requests.get('http://localhost:9200')
es = Elasticsearch([{'host':'localhost','port':'9200'}])
es.indices.create(
index='dictionary',
body={
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
}
}
}
)
그다음으로는 mapping 설정을 해주어야 합니다. mapping은 관계형 데이터베이스의 schema와 비슷한 개념으로, Elasticsearch의 인덱스에 들어가는 데이터의 타입을 정의하는 것입니다.
mapping 설정을 직접 해주지 않아도 Elastic에서 자동으로 mapping이 만들어지지만 사용자의 의도대로 mapping 해줄 것이라는 보장을 받을 수 없습니다.
mapping이 잘못된다면 후에 Kibana와 연동할 때도 비효율적이기 때문에 Elastic에서는 mapping을 직접 하는 것을 권장합니다.
각 필드의 타입을 정의하고 위에서 설정해준 분석기 ‘my_analyzer’로 음식점 이름과 리뷰를 분석할 수 있도록 설정해줍니다.
es.indices.create(
index='dictionary',
body={
# 한글 형태소 분석기 nori를 통해 데이터를 토크나이징할 수 있도록 설정
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
}
},
# Elasticsearch의 인덱스에 들어가는 데이터의 타입을 정의
# 설정해준 분석기 ‘my_analyzer’로 Restaurant과 Review를 분석할 수 있도록 설정
"mappings": {
"properties": {
"Restaurant": {
"type": "text",
"analyzer": "my_analyzer"
},
"Review": {
"type": "text",
"analyzer": "my_analyzer"
},
"id": {
"type": "long"
}
}
}
}
)
JSON 파일 index import
Json 포맷의 데이터를 한 줄씩 읽어서 index에 import 하기 좋은 형태로 만들어줍니다.
# 여러 개의 데이터를 한 번에 bulk하기 위해서 데이터를 Elasticsearch 형식에 맞게 정제
directory_path = '/Users/byeongheon/programmers/final_project/data/'
with open(directory_path + 'test.json', encoding='utf-8') as json_file:
json_data = json.loads(json_file.read())
body = ""
count = 1
for i in json_data:
body = body + json.dumps({"index": {"_index": "dictionary", "_id": count}}) + '\n'
body = body + json.dumps(i, ensure_ascii=False) + '\n'
if count == 1:
print(body)
count += 1
f = open(directory_path+'input.json', 'w')
f.write(body)
f.close()
es.bulk(body)
결과는 아래와 같습니다.
# input.json
{"index": {"_index": "dictionary", "_id": 1}}
{"Restaurant": "흥부찜닭-신촌점", "Review": "기본맛 맛있게맵고 양도 많네요", "id": 1}
{"index": {"_index": "dictionary", "_id": 2}}
{"Restaurant": "흥부찜닭-신촌점", "Review": "가성비 만족스럽네요 ㅎ", "id": 2}
{"index": {"_index": "dictionary", "_id": 3}}
{"Restaurant": "흥부찜닭-신촌점", "Review": "재료 상태도 좋고 맛도 적당히 매콤해서 좋아요 당면도 중국식당면 좋아하는디 맛있네요 배달도 빠르고 양도 꽤많습니다 3번정도 나눠먹어여 보통", "id": 3}
{"index": {"_index": "dictionary", "_id": 4}}
...
Json Data Import 하기
이제 elasticsearch의 index에 생성한 JSON 포맷의 파일을 import 해주겠습니다.
7.xx 버전이상은 content 타입을 명시해야 합니다. json 타입으로 설정하고 post로 데이터를 엘라스틱 서치에 올려줍니다.
bulk를 사용하는 정확한 방법은 이 문서를 참조해 주시길 바랍니다.
curl -X POST "http://localhost:9200/dictionary/_bulk" \
-H 'Content-Type: application/json' --data-binary \
@/Users/byeongheon/programmers/final_project/data/input.json
장고 어플리케이션 만들기
다음은 장고에서 작성한 views.py 파일입니다. 다음과 같이 API를 간단하게 구성해서 GET 요청으로 쿼리 결과를 받아올 수 있습니다.
# django search app view file
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from elasticsearch import Elasticsearch
class SearchView(APIView):
def get(self, request):
es = Elasticsearch([{'host':'localhost','port':'9200'}])
# 검색어
search_word = request.GET.get('search')
if not search_word:
return Response(status=status.HTTP_400_BAD_REQUEST, data={'message': 'search word param is missing'})
docs = es.search(
index='dictionary',
body={
"query": {
"multi_match": {
"query": search_word,
"fields": [
"Restaurant",
"Review"
]
}
}
})
data_list = []
for data in docs['hits']['hits']:
data_list.append(data.get('_source'))
return Response(data_list)
결과
결과를 보기 위해 서버를 실행시켜줍니다.
$ python manage.py runserver
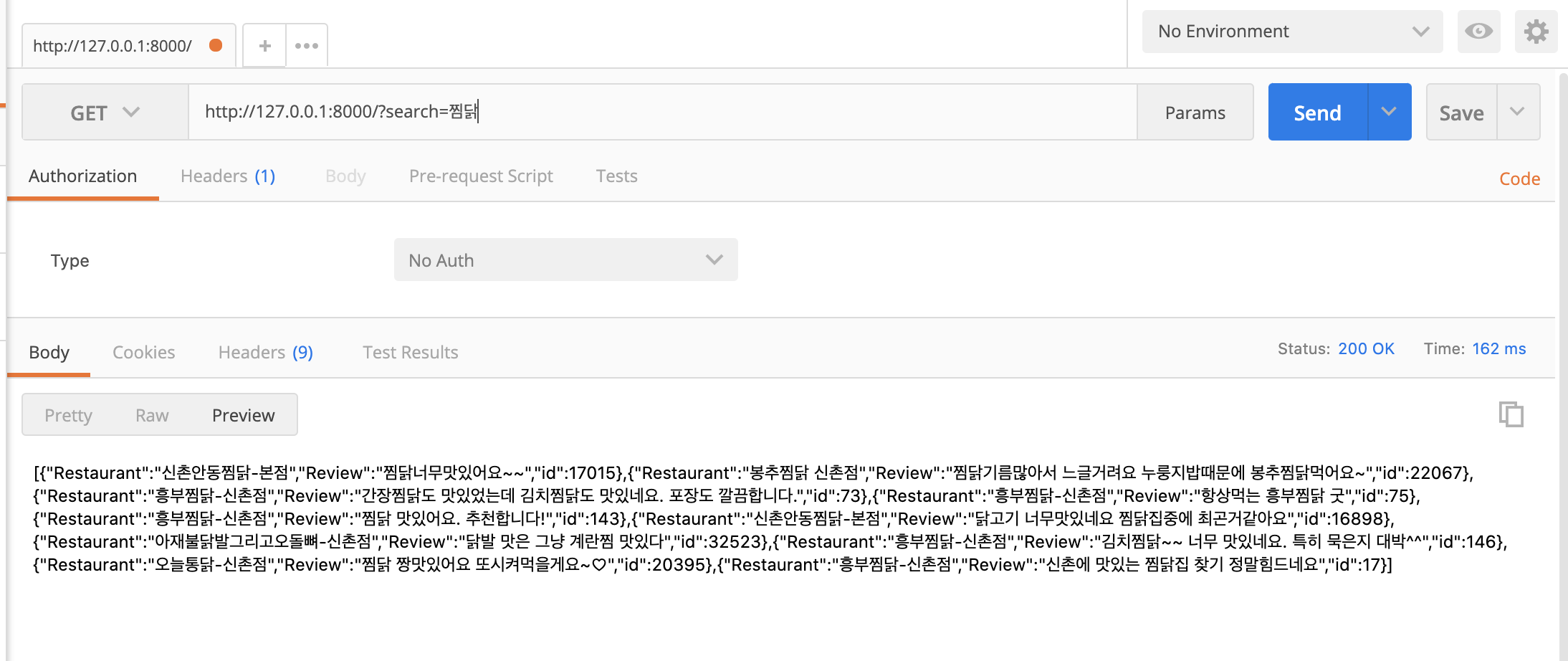
포스트맨을 통해서 쿼리를 주면 다음과 같이 결과가 나오는 것을 확인하실 수 있습니다.
댓글남기기