NLP: 단어 임베딩
단어간의 관계를 잘 표현하면서 나타낼 수 있는 방법을 알아보도록 합시다.
단어의 의미는 분포적 유사도를 이용해 표현해볼 수 있습니다.
벡터공간 내에서 비슷한 단어들은 가까이 있게 설정합니다.

임베딩 (embedding)
벡터로 의미 표현하기
벡터로 표현된 단어를 임베딩 이라고 부릅니다. 보통은 밀집벡터인 경우를 임베딩이라고 부릅니다. 최근 NLP 방법들은 모두 임베딩을 사용해서 단어의 의미를 표현합니다.
임베딩 사용 이유
- 임베딩을 사용하지 않을 경우
- 각 속성은 한단어의 존재 유무라 가정
- 학습데이터와 테스트데이터에 동일한 단어가 나타나지 않으면 예측결과가 좋지 못함
- 임베딩을 사용할 경우
- 각 속성은 단어 임베딩 벡터
- 테스트데이터에 새로운 단어가 나타나도 학습데이터에 존재하는 유사한 단어를 통해 학습한 내용을 이해
임베딩을 사용하게 되면 단어의 존재유무보다 단어의 특성이 더 중요해집니다.
임베딩의 종류
- 희소벡터(sparse vector)
- tf-idf
- vector propagation (검색엔진을 위한 질의, 문서 표현)
- 밀집벡터(dense vector)
- word2vec
- glove
word2vec
주어진 단어 w를 인접한 단어들의 빈도수로 나타내는 대신, 주변 단어를 예측하는 분류기를 학습하는 형태로 발전된 것이 밀집벡터 형태의 임베딩입니다.
단어 w가 주어졌을 때 단어 c가 주변에 나타날 확률을 구하는 것과 같습니다.
모델내 단어 w의 가중치 벡터에 중점을 두면, 모댈을 학습하기 위한 목표값이 이미 데이터 내에 존재하기 때문에 사람이 수동으로 레이블을 생성할 필요가 없습니다.
skip-gram
skip-gram 모델은 한 단어가 주어졌을 때 그 주변 단어를 예측할 확률을 최대화하는 것이 목표입니다. 즉, 단어들의 시퀀스 $w_1, … , w_T$가 주어졌을 때, 다음 확률을 구하는 것 입니다.
학습할 때 사용되는 파라미터는 두가지가 있습니다. W(target word embedding)와 C(context & noise embedding) 두개의 행렬이 주어집니다. 이 두개의 행렬은 같은 크기를 지닙니다.
하나의 목표단어 w와 상황단어 c가 주어졌을 때 $p(c\midw)$를 구하는 것이 목표가 됩니다.
exp(u_c^T v_w)$ 의 softmax를 구하는 것과 동일한 문제입니다.
여기서 $x_w$를 단어 $w$에 대한 one-hot 벡터라 하면, $v_w$ 와 $u_c$는 다음과 같이 정의됩니다.
\(v_w = (x_w^T W)^T, u_c = (x_c^T C)^T\)
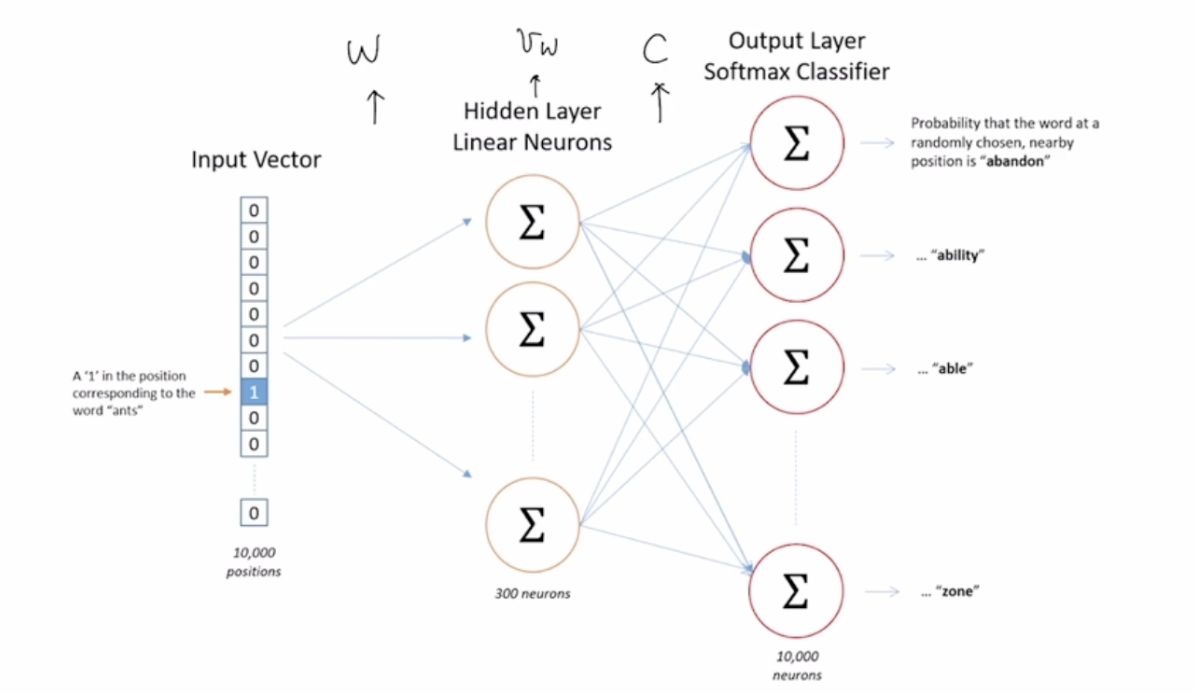
이러한 모델은 한가지 큰 단점을 가지고 있습니다. softmax를 처리하는 과정에서 Normalization constant가 너무 커서 연산량이 많아지게 됩니다.
이에 대한 해결책으로 이 분모에 해당하는 식을 하나의 파라미터로 학습합니다. 이를 Noise-constrastive estimation이라 합니다.
이진분류문제에 해당하는 새로운 목표함수를 최적화시킴으로써 원래 likelihood의 최적해를 근사합니다.
이를 단순화 시키면 negative sampling이 됩니다. word2vec이 negative sampling을 사용합니다.
댓글남기기