모델 기반 협업 필터링을 살펴봅시다.
SVD 알고리즘
사용자/아이템 기반 협업 필터링의 문제점
- 확장성(scalability): 큰 행렬 계산은 여러모로 쉽지가 않습니다.
- 아이템 기반으로 가면 계산량이 줄어듭니다.
- Spark를 사용하면 큰 행렬 계산이 가능합니다.
- 부족한 데이터
- 많은 사용자들은 충분한 수의 리뷰를 남기지 않습니다.
- 해결책
- 모델 기반 협업 필터링
머신러닝 기술을 사용해 평점을 예측하고 입력은 사용자-아이템 평점 행렬을 사용합니다.
행렬 분해(Matrix Factorization) 방식과 딥러닝 방식이 있습니다.
- 모델 기반 협업 필터링
머신러닝 기술을 사용해 평점을 예측하고 입력은 사용자-아이템 평점 행렬을 사용합니다.
행렬 분해 방식
- 협업 필터링 문제를 사용자-아이템 평점 행렬을 채우는 문제로 재정의 해봅니다.
- 사용자 혹은 아이템을 적은 수의 차원으로 축소함으로써 문제를 간단화 합니다.
- 가장 많이 사용되는 행렬 분해 방식은 다음과 같습니다.
- PCA(Principal Component Analysis)
- SVD(Singular Vector Decomposition) 혹은 SVD++
PCA(Principal Component Analysis)
차원을 축소하되 원래 의미는 최대한 그대로 간직하고자 하는 방식입니다.
예를 들어 유저와 영화의 이름으로 이루어진 행렬이 있다 가정했을 때 영화들이 가지고 있는 공통적인 특징(장르, 연도)들로 차원을 축소하는 방법이 있습니다.
행렬 자체의 크기를 줄일 수 있다는 장점이 있지만 차원 축소에 사용된 방식이 기준이 되기 때문에 유의해야 합니다.
SVD(Singular Vector Decomposition)
2개 혹은 3개의 작은 행렬의 곱으로 단순화 시키는 과정으로 행렬을 분해합니다. 일종의 소인수 분해라고 생각할 수 있습니다.
- 사용자-아이템 행렬을 훨씬 작은 3개의 행렬($U, \sigma, V^t$)로 나눠 표현합니다.
- U: 사용자를 나타내는 훨씬 작은 행렬입니다.
- $\sigma$: U의 특정 부분의 시그널을 증폭시켜주는 대각행렬 입니다. 행렬을 살펴보면 덜 중요한 부분을 파악할 수 있습니다.
- $V^t$: 아이템을 나타내는 훨씬 작은 행렬입니다.
SVD++
Netflix contest에서 고안된 추천방식입니다.
- SVD나 PCA는 완전하게 채워져있는 행렬의 차원수를 줄이는 방식입니다.
- SVD++는 sparse 행렬이 주어졌을 때 비어있는 셀들을 채우는 방법을 학습하는 알고리즘입니다.
- 채워진 셀들의 값을 최대한 비슷하게 채우는 방식으로 학습합니다. 보통 RMSE(route mean square error)의 값을 최소화하는 방식으로 학습하면서 SGD를 사용합니다.
- 사용자-아이템 행렬이 입력값으로 들어가면 $U, \sigma, V^t$를 찾아냅니다.
- surprise 라이브러리 혹은 scikit-learn의 TruncatedSVD를 사용합니다.
SVD 기반 추천 엔진
surprise 라이브러리와 무비렌즈 데이터셋을 이용해서 평점을 예측하는 모델을 개발해봅시다.
영화 평가에 대한 실제 데이터셋인 무비렌즈는 미네소타 대학의 그룹렌즈(FroupLens)프로젝트에 의해 개발되었으며, https://grouplens.org/datasets/ 사이트에서 데이터를 다운받을 수 있습니다.
tar.gz나 zip포맷 중에 하나를 골라서 100,000개의 데이터셋을 다운 받으면 되겠습니다.
실습은 colab에서 진행하고 모델의 성능 평가는 test/train 방식으로 진행합니다.
! pip install surprise
데이터 로딩 및 분석
from surprise import Dataset
from surprise import Reader
from collections import defaultdict
import numpy as np
import pandas as pd
movies = pd.read_csv("경로/movies.csv")
ratings = pd.read_csv("경로/movielens/ratings.csv")
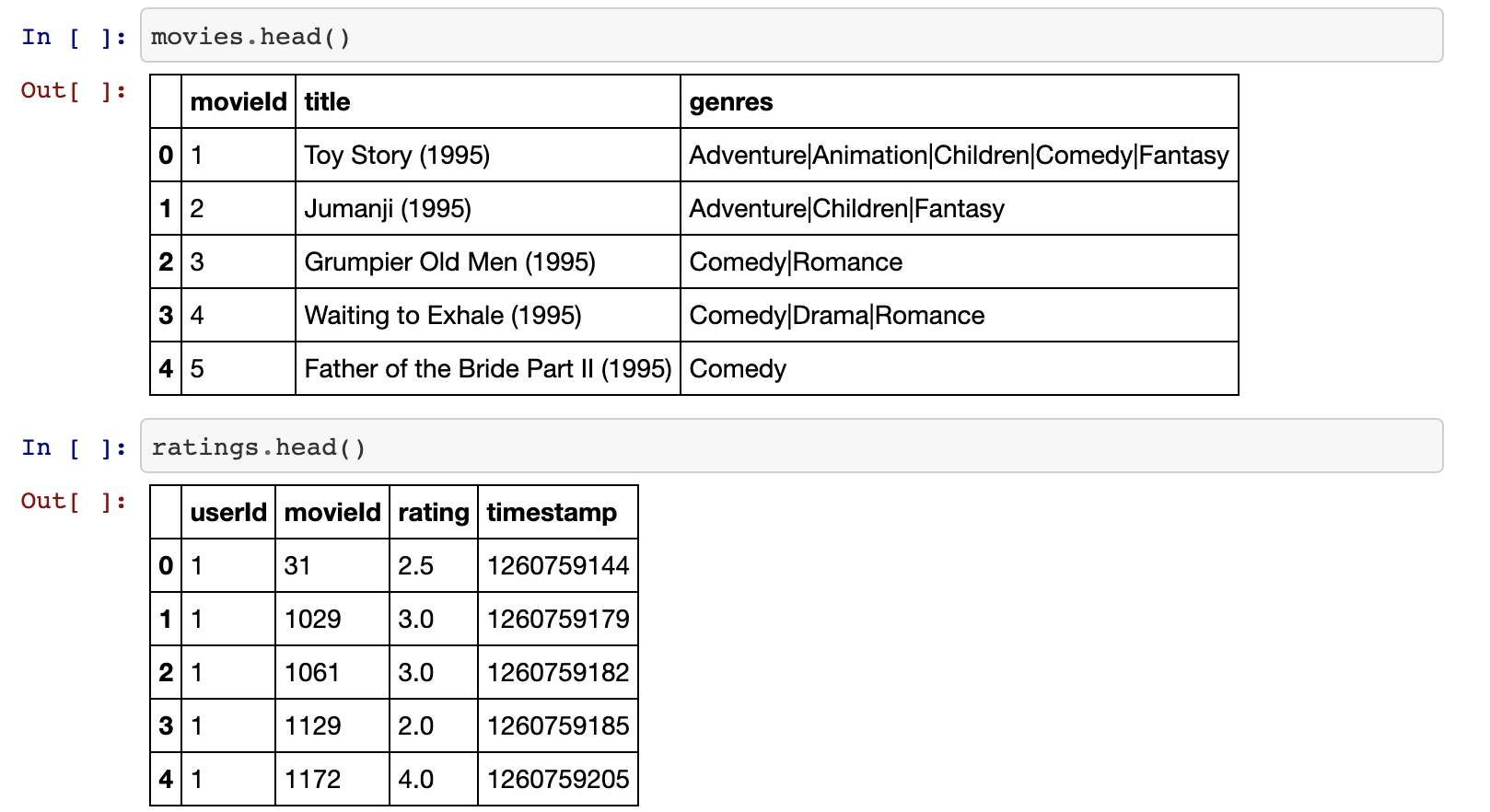
movie_ratings = pd.merge(movies, ratings, left_on='movieId', right_on='movieId')

아이템 기반의 테이블을 보시면 데이터가 얼마나 sparse 한지 직접 확인해볼 수 있습니다.
item_ratings = ratings.pivot_table(index=['userId'],columns=['movieId'],values='rating')

GridSearchCV 사용해서 최적의 하이퍼파라미터 학습시키기
from surprise import KNNBasic
import heapq
from collections import defaultdict
reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1)
data = Dataset.load_from_file("ratings.csv", reader=reader)
from surprise import SVD
from surprise import NormalPredictor
from surprise.model_selection import GridSearchCV
# 하이퍼 파라미터 그리드 검색을 해서 최적의 파라미터를 찾는다.
# scikit-learn의 cv와 아주 유사함
# n_factors: 축소 차원수 (n*n의 스케일 행렬, 가운데 행렬 크기 지정)
# n_epochs: 전체 데이터 셋을 훈련시키는 횟수
# lr_all: 학습률
param_grid = {
'n_epochs' : [20, 30],
'lr_all' : [0.005, 0.010],
'n_factors' : [50, 100]
}
# 3-폴드 교차검증(cv) 사용, 비용함수는 2개 (데이터를 3개의 chunk로 나눠서 빌드하고 훈련합니다.)
gs = GridSearchCV(SVD, param_grid, measures=['rmse','mae'],cv=3)
gs.fit(data)
다음과 같은 결과를 얻을 수 있습니다.

최고의 성능을 보인 파라미터로 훈련하고 예측하기
svd = gs.best_estimator['rmse']
trainset = data.build_full_trainset()
svd.fit(trainset)
다음과 같이 특정 유저와 아이템을 가지고 예측을 시도해보면 결과를 얻을 수 있습니다.

Train/Test Split으로 훈련하고 성능 평가해보기
from surprise import accuracy
from surprise.model_selection import train_test_split
trainset, testset = train_test_split(data, test_size=.25)
svd = SVD() # 여기서 하이퍼 파라미터는 디폴트로 들어갑니다.
svd.fit(trainset)
predictions = svd.test(testset)
accuracy.rmse(predictions)
테스트 셋의 데이터를 확인해보고 모델로 특정 케이스를 검증해봅시다.

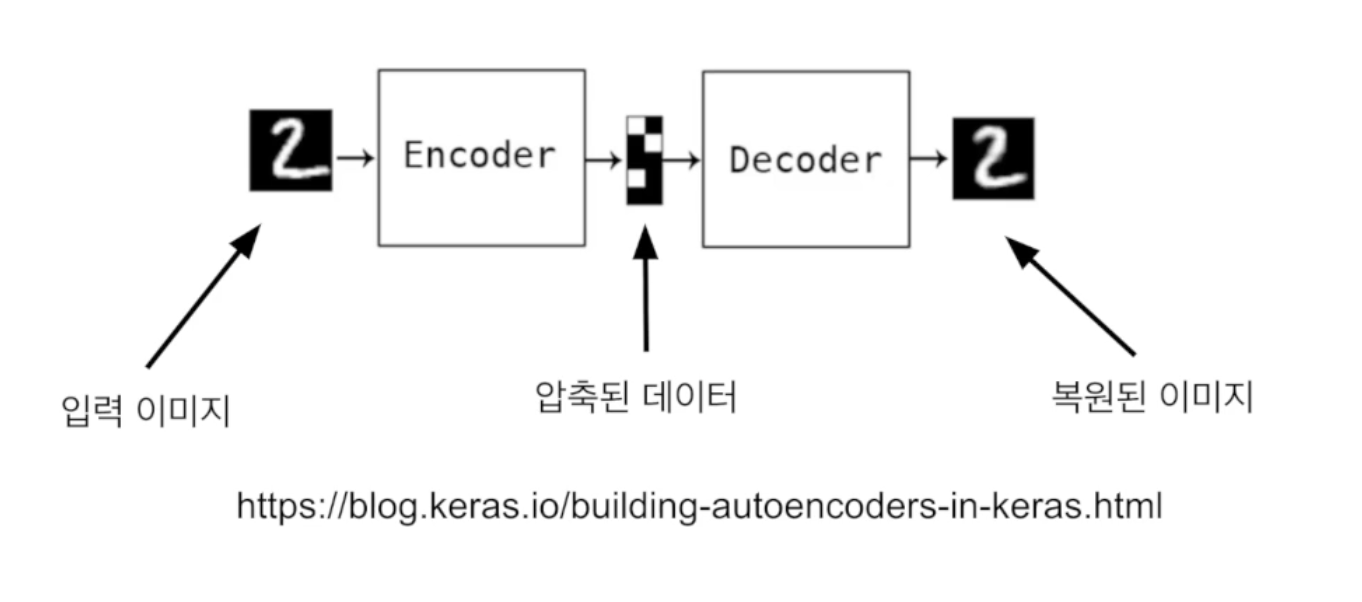
오토인코더
오토인코더는 대표적인 비지도학습을 위한 딥러닝 모델입니다.
데이터의 숨겨진 구조를 발견하면서 노드의 수를 줄이는 것이 목표입니다.
입력 데이터에서 불필요한 특징들을 제거한 압축된 특징을 학습합니다.
오토인코더의 출력은 입력을 재구축한 것으로서, 입력값을 최대한 비슷하게 출력하기 위한 딥러닝 모델이라 할 수 있습니다.
오토인코더의 구조
- 출력층의 노드 개수와 입력층의 노드 개수가 동일해야합니다.
- 은닉층의 노드 개수가 출력츰/입력층의 노드 개수보다 작아야합니다.
- 이렇게 학습된 은닉층의 출력을 입력을 대신하는 데이터로 사용함으로써 데이터의 입력 크기를 줄이는 효과를 낼 수 있습니다.
오토인코더를 이용한 인코딩 & 디코딩
먼저 간단한 실습을 위한 모듈들을 import 해줍니다.
import numpy as np
import matplotlib.pyplot as plt
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
데이터는 keras의 mnist 데이터셋을 이용할 것입니다.
학습에 사용될 데이터와 검증에 사용될 데이터가 나누어져 있습니다.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 256
x_test = x_test.astype('float32') / 256
print(x_train.shape)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11493376/11490434 [==============================] - 0s 0us/step
(60000, 28, 28)
x_train = x_train.reshape(len(x_train), 28*28)
x_test = x_test.reshape(len(x_test), 28*28)
print(x_train.shape)
print(x_test.shape)
(60000, 784)
(10000, 784)
이제 딥러닝 모델을 설계해봅시다.
keras의 functional API를 사용하면 다음과 같이 모델을 구축할 수 있습니다.
각각의 레이어들의 input을 다른 레이어들의 출력으로 설정할 수 있습니다.
input_layer = Input(shape=(784,))
encoded = Dense(64, activation='relu')(input_layer)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_layer, decoded)
다음과 같이 encoder만 따로 만들 수 있습니다.
encoder = Model(input_layer, encoded)
다음은 decoder를 만드는 과정입니다.
input_layer_decoder = Input(shape=(64,))
decoder_layer = autoencoder.layers[-1](input_layer_decoder)
decoder = Model(input_layer_decoder,decoder_layer)
다음 코드를 통해 모델의 구조를 한눈에 볼 수 있습니다.
autoencoder.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 784)] 0
_________________________________________________________________
dense (Dense) (None, 64) 50240
_________________________________________________________________
dense_1 (Dense) (None, 784) 50960
=================================================================
Total params: 101,200
Trainable params: 101,200
Non-trainable params: 0
_________________________________________________________________
다음과 같이 학습을 진행할 수 있습니다.
입력이 다시 label 정보에 그대로 쓰입니다.
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
autoencoder.fit(x_train,x_train, epochs=50, batch_size=256, shuffle=True, validation_data=(x_test,x_test))
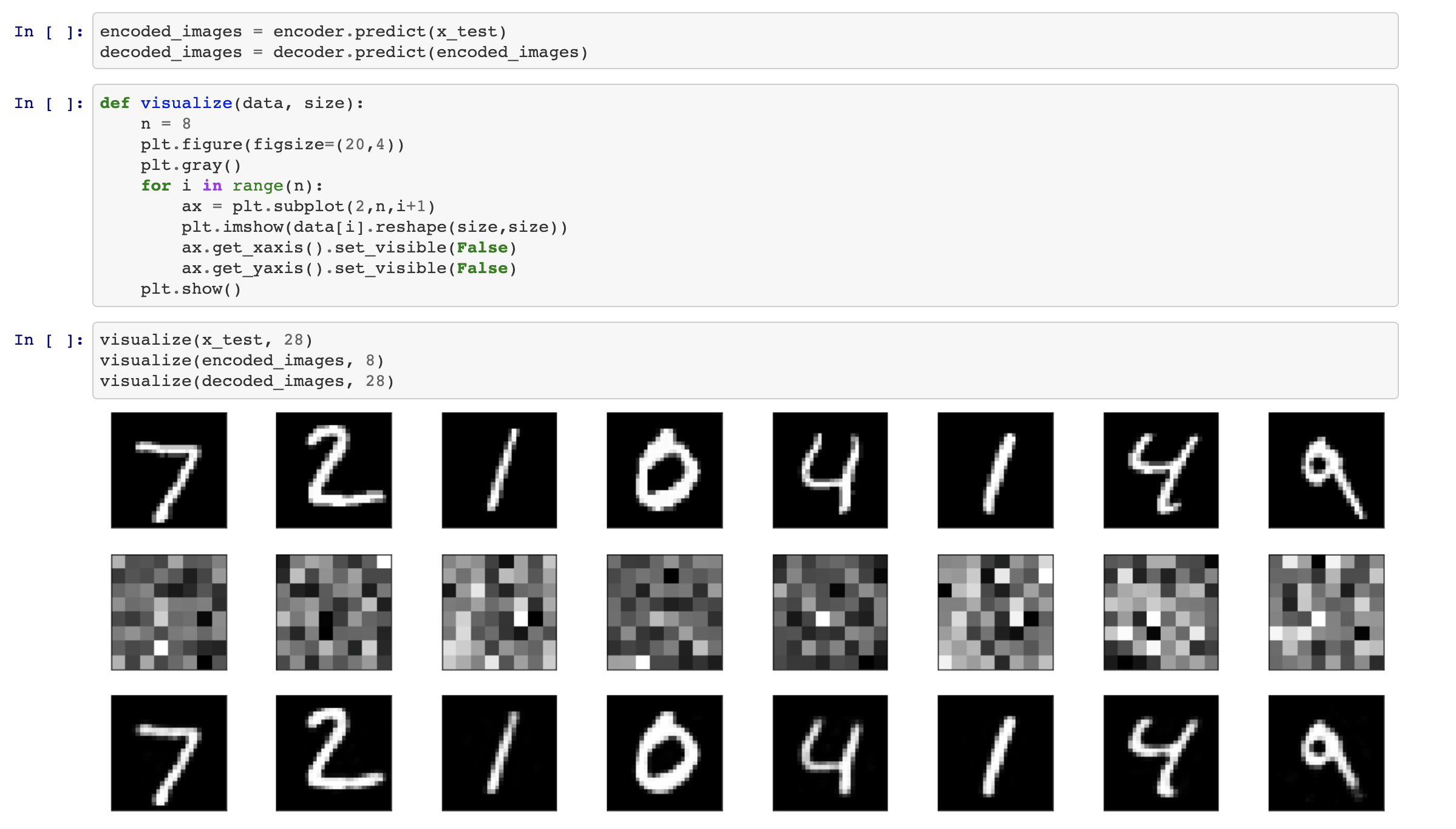
학습된 인코더와 디코더를 통해서 이미지들이 어떻게 임베딩되고 다시 원본으로 돌아가는지 살펴봅시다.
pyplot을 이용해서 받아온 텐서를 2차원 이미지로 변환시키는 함수를 작성합니다.
결과는 다음과 같습니다.
댓글남기기