추천엔진의 기본적인 구조에 대해 간략하게 알아봅시다.
추천 시스템
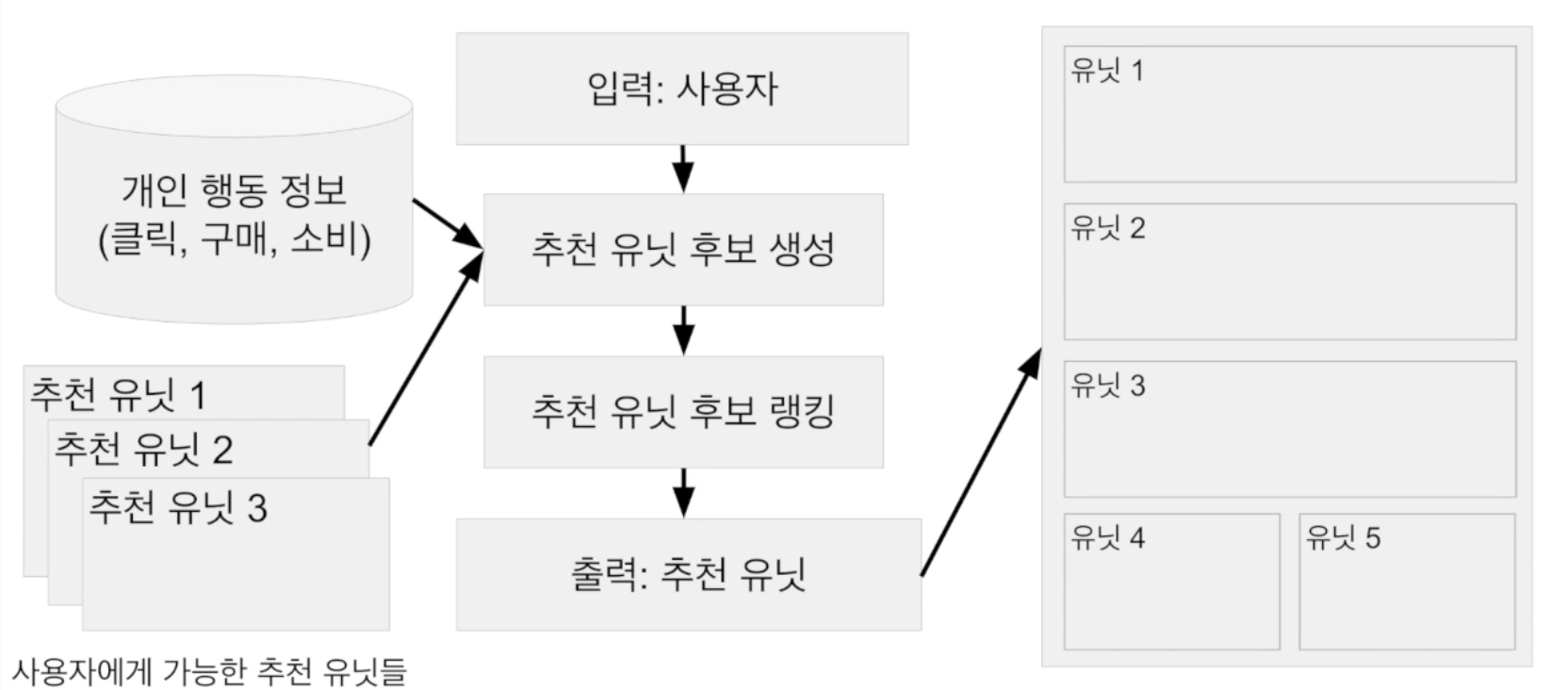
-
개인에 대한 정보를 바탕으로 어떤 유잇을 생성할 수 있을 지 후보를 만듭니다. (어떤 matrix를 개선시켜야 하는지 목표가 있다면 좋습니다.)
-
후보들의 점수를 매겨서 추천 유닛의 랭킹을 만듭니다.
-
랭킹을 기반으로 몇개의 추천유닛을 선정해 페이지에 출력합니다.
유닛
유닛의 주제를 선정하면 유닛을 목적에 맞게 설계합니다.
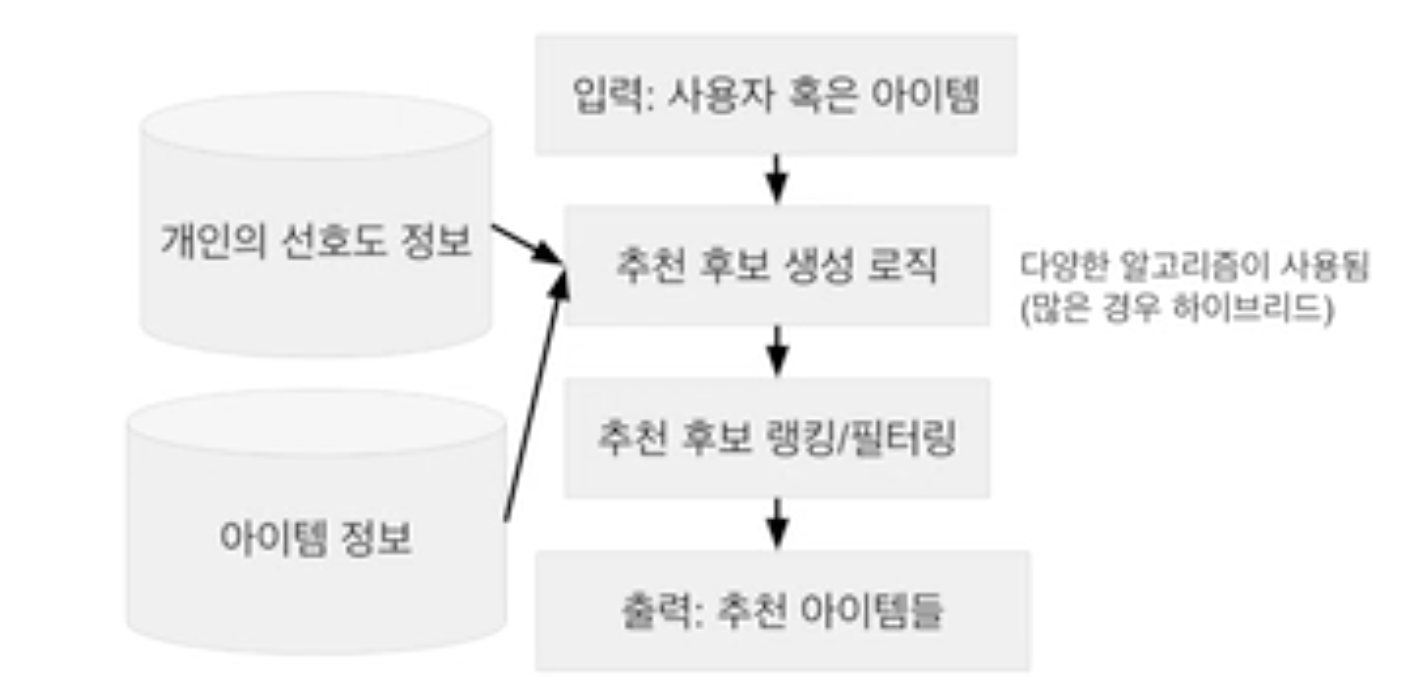
각 유닛의 목표는 어떤 아이템을 보여줄지 어떤 순서로 보여줄지 정해주는 것입니다.
유닛은 객관적인 측정으로 지표가 계산될 수 있어야 합니다.
- 유닛 설계의 예시
- 배치로 매일 밤에 지난 90일간 방문했던 사용자들과 어느 조건이 충족되는 강의들의 페어에 대해 각종 확률을 예측 (여러개의 모델을 실행 - 강의 가격, 강의 들은 빈도, 강의 평가, 강의 등록 확률 모델 등등)
- 모델이 너무 많은 시간과 리소스를 필요로 할 수 있습니다.
- 모든 사용자들을 대상으로 계산을 진행하므로 효율이 떨어집니다.
- 메세지 큐와 NoSQL등을 이용해서 추천 계산을 실시간으로 진행하도록 만들 수 있습니다. 각종 모델 예측기능을 API로 노출합니다. 일부 피처는 배치로 계산합니다. (하둡/spark)
- 배치로 매일 밤에 지난 90일간 방문했던 사용자들과 어느 조건이 충족되는 강의들의 페어에 대해 각종 확률을 예측 (여러개의 모델을 실행 - 강의 가격, 강의 들은 빈도, 강의 평가, 강의 등록 확률 모델 등등)
대표적인 3가지의 추천 엔진
기본적으로 다른 사용자들의 정보를 이용해서 취향을 예측하는 방식이 있습니다. 크게 세 종류가 존재합니다.
- 사용자 기반
- 비슷한 패턴을 보이는 유저들을 찾아서 그 유저들이 높게 평가한 아이템을 추천합니다.
- ex)당신과 비슷한 사용자들이 좋아하는 아이템
- 아이템 기반
- 평가가 비슷한 패턴을 보이는 아이템들을 찾아서 그 아이템들을 추천합니다.
- ex)이 아이템을 좋아한 다른 유저들이 좋아하는 아이템
- 예측모델 기반
- 평점을 예측하는 머신러닝 모델을 만들어서 추천합니다.
구현방식
구현하는 방식에는 크게 두 종류가 존재합니다.
- 메모리 기반
- 코사인 유사도나 피어슨 상관계수 유사도를 사용해 비슷한 사용자 혹은 아이템을 찾습니다.
- 평점을 예측할 때는 가중치를 사용한 평균을 사용합니다.
- 이해하기 쉽고 설명하기 쉽지만 스케일하기 힘듭니다.(평점 데이터가 부족할경우 등)
- 모델 기반
- 머신러닝을 사용해 평점을 예측합니다. (PCA, SVD, Matrix Factorization, 딥러닝/오토인코더 등)
- 행렬의 차원을 줄임으로써 평점 데이터의 부족 문제를 해결합니다.
- 어떻게 동작하는지 설명하기 힘듭니다. (머신러닝이 가지고 있는 일반적인 문제들)
추천엔진 평가방법
- 메모리 기반 협업 필터링
- 평점의 예측 없이 유사도 기반으로 추천하기 때문에 RMSE와 같은 평점 기반으로 평가가 불가능합니다.
- 보통 TOP-N(혹은 nDCG) 방식으로 평가합니다.
- TOP-N은 사용자가 좋아한 아이템을 일부 남겨두었다가 추천 리스트에 포함되어 있는지 보는 방식입니다.
- 추천 순서를 고려한다면 normalized Discounted Cumulative Gain(nDCG)로 평가할 수 있습니다.
- 모델 기반 협업 필터링
- 머신러닝 알고리즘들이 사용하는 일반적인 방식(RMSE 등)으로 성능을 평가할 수 있습니다.
- 메모리 기반의 평가방식도 사용할 수 있습니다.
- 온라인 테스트 (A/B 테스트)
- 가장 좋은 방식이지만 현실적으로 할 수 없을 때가 많습니다.
머신 러닝 모델 평가 방법
- 먼저 지표를 설정합니다.
- Confusion matrix, AUC-ROC, F1 score
- RMSE, MAE, Log Loss
- 평가 방법을 결정합니다.
- 홀드 아웃 테스트 (Train & Test)
- 교차 검증 (K-Fold, Cross Val)
- 일반적으로 홀드 아웃보다 오버피팅 이슈가 적어서 모델이 안정적입니다.
- 특수한 교차 검증 방식: Leave One Out Cross Validation
- 교차 검증에서 폴드 수가 트레이닝 데이터 레코드 수와 동일한 경우입니다.
- 테스트를 한 예제를 대상으로 진행합니다. 오랜시간이 필요합니다.
Top-N 추천 정확도 기반
- 사용자별로 일부 높은 평점 레코드를 따로 빼놓고 나중에 추천되는 아이템들과의 일치율을 계산합니다.
- LOOCV 테스트 방법과 병행해서 사용합니다.
- scikit-learn, surprise 등의 라이브러리에서 지원합니다.
댓글남기기