라이브러리를 이용해 데이터 수집하기
본 프로그램은 사이트의 html 태그 구조의 의존하는 형태입니다.
코드에 따라 전혀 다른 결과가 도출될 수 있습니다.
‘나무위키 뉴스’의 텍스트 데이터를 BeautifulSoup로 수집한 다음, 데이터 내에서 등장하는 키워드의 빈도를 분석해보겠습니다.
이를 통해 현재 이슈가 되고 있는 키워드가 무엇인지 분석할 수 있을 것입니다.
페이지 살펴보기
먼저 크롤링을 하기 위한 페이지를 열어보겠습니다. 저는 나무위키의 뉴스 페이지를 먼저 살펴볼 예정이므로 https://namu.news/section/news 에 접속해 페이지의 구조를 살펴보도록 하겠습니다.
개발자 도구를 열어 페이지를 확인해보면 해당 페이지의 정보를 볼 수 있습니다.
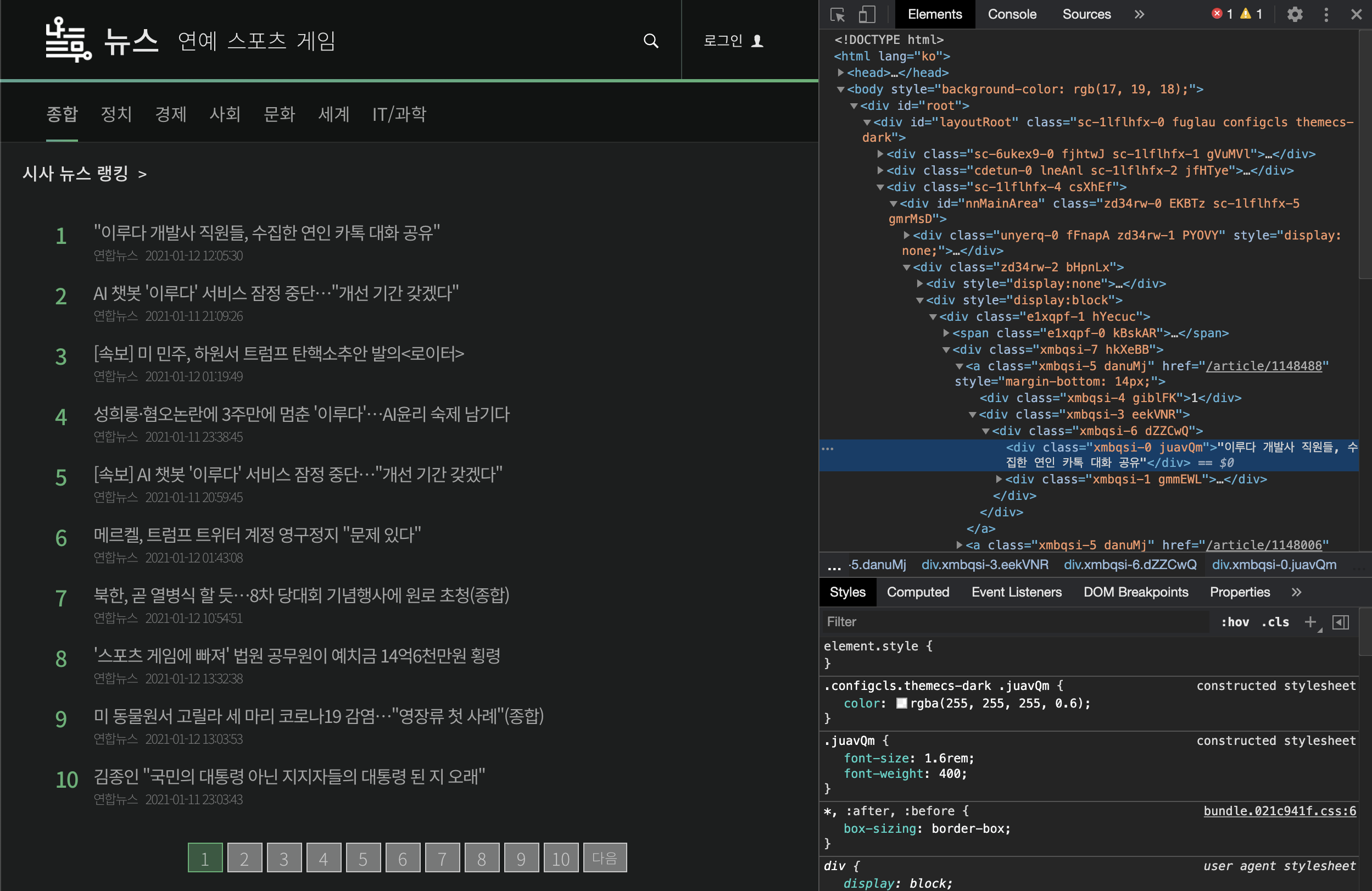
뉴스의 텍스트 데이터에 접근하기 위해 뉴스들의 url을 먼저 추출합니다. 개발자 도구 상단의 마우스 포인터 아이콘을 클릭한 후, url 정보를 확인하고 싶은 페이지의 링크을 클릭합니다. 클릭을 하면 다음과 같이 url 주소를 확인해 볼 수 있습니다.
웹 크롤링 라이브러리
파이썬에서는 BeautifulSoup와 requests 라이브러리를 사용해보도록 하겠습니다.
requests는 특정 url로부터 HTML 문서를 가져오는 작업을 처리하고, BeautifulSoup는 문서에서 데이터를 뽑는 작업을 수행합니다. 이 모듈을 사용하기 위해서는 lxml, beautifulsoup4 requests 모듈을 설치해야 합니다. pip install을 이용해 설치해주도록 합시다.
페이지 url 수집하기
이제 BeautifulSoup 이용해 url을 통해 문서 정보를 가져오고
데이터를 추출해볼 수 있습니다.
import requests
from bs4 import BeautifulSoup
# 크롤링할 사이트 주소 정의
source_url = "https://namu.news/section/news?page="
table_rows = []
# 페이지를 넘겨가면서 a 태그 크롤링 수행, list 만들어주기
for page in range(5):
req = requests.get(source_url+str(page+1))
html = req.content
soup = BeautifulSoup(html, 'lxml')
contents_table = soup.find(name="div", attrs={"class":"xmbqsi-7"})
table_rows.extend(contents_table.find_all(name="a"))
# a 태그의 href 속성을 리스트로 추출
page_url_base = "https://namu.news"
page_urls = []
for row in table_rows:
if len(row) > 0:
page_url = page_url_base + row.get('href')
page_urls.append(page_url)
# 중복 url 제거
page_urls = list(set(page_urls))
# 페이지 확인
for page in page_urls:
print(page)
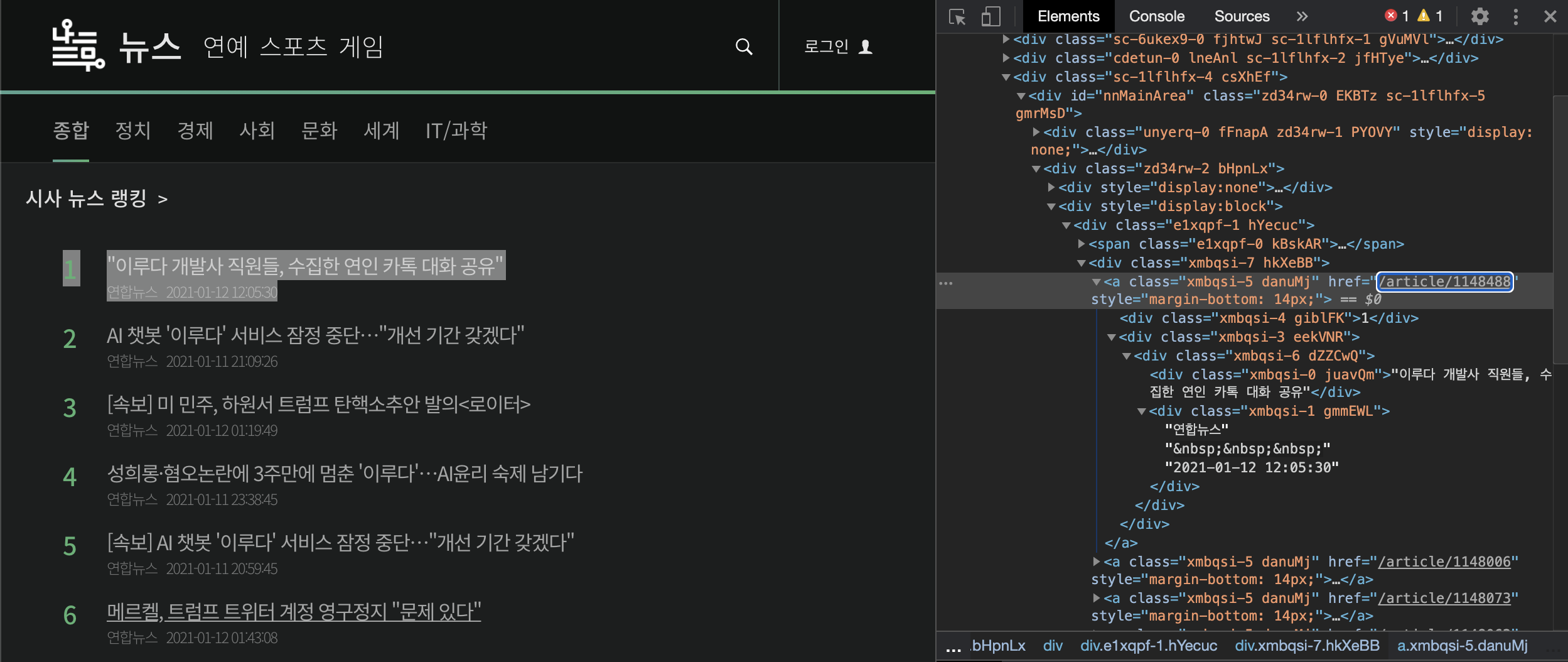
위 코드는 개발자 도구로 살펴본 HTML 구조를 이용해 url을 뽑아내는 코드입니다.
기사의 url이 div (class = hkXeBB) -> a 안에 존재하기 때문에 위 코드와 같이 계층구조를 좁히면서 매핑을 시켜줍니다.
이러한 과정을 페이지를 이동해가며 반복하면 a 태그의 리스트가 만들어집니다.
리스트의 아이템에서 get 함수를 이용해 href 속성값만을 추출해 낸 뒤 이를 완성된 url로 만들어 줍니다.
텍스트 정보 수집하기
다음으로 수집한 url에서 특정정보를 스크랩해오는 코드를 작성합니다.
import pandas as pd
import re
# 제목과 본문을 받아올 dataframe 만들기
columns = ['title', 'content_text']
df = pd.DataFrame(columns=columns)
# url에서 제목과 본문을 bs4를 이용해 스크래핑 해오기
for page_url in page_urls:
req = requests.get(page_url)
html = req.content
soup = BeautifulSoup(html, 'lxml')
title = soup.find(name = "div", attrs={"class":"sc-1gwvzpi-1"})
article = soup.find(name = "article", attrs={"class":"sc-1gwvzpi-18"})
if title is not None:
row_title = title.get_text(separator=" ").strip()
else:
row_title = ""
if article is not None:
row_article = article.get_text(separator=" ").strip()
else:
row_article = ""
row = [row_title, row_article]
series = pd.Series(row, index=df.columns)
df = df.append(series, ignore_index=True)
# 텍스트에서 한국어만 정규식을 이용해 추출해냅니다.
def text_cleaning(text):
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+')
result = hangul.sub('',text)
return result
df['title'] = df['title'].apply(lambda x: text_cleaning(x))
df['content_text'] = df['content_text'].apply(lambda x: text_cleaning(x))
# 제목과 본문이 잘 불러와졌는지 확인해봅니다.
title_corpus = " ".join(df['title'].tolist())
content_corpus = " ".join(df['content_text'].tolist())
print(title_corpus)
위와 같은 과정을 통해서 특정 url에 있는 데이터들을 스크랩 해올 수 있습니다.
키워드 추출하기
konlpy를 이용해서 텍스트의 키워드를 추출해 보도록 하겠습니다.
konlpy를 사용하기 위해서는 몇가지 모듈을 설치하는 등의 준비과정이 필요합니다.
자세한 설치내용은 공식 문서를 참고하시길 바랍니다.
https://konlpy-ko.readthedocs.io/ko/v0.4.3/install/
다 설치를 완료하고 확인을 해보니 다음과 같은 오류가 발생합니다.

JVM 관련 메소드에 어떤 문제가 발생한 듯 합니다.
문제를 일으키는 소스코드로 가서 convertString을 True로 설정하는 라인을 지워줍니다.
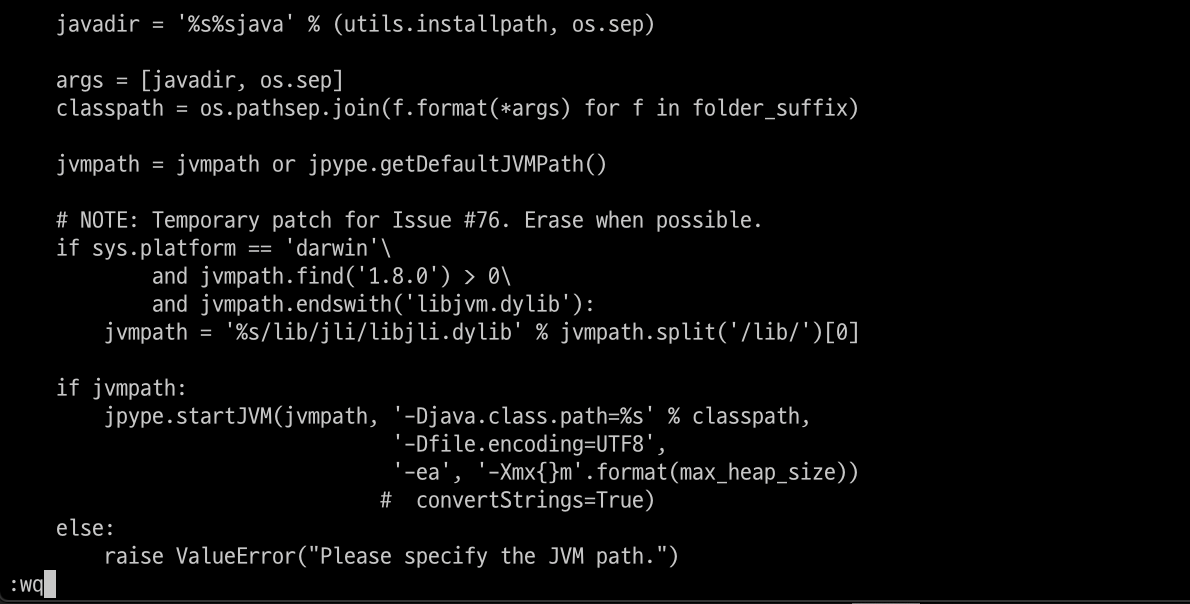
기본 default 값이 True로 설정되어 있어 그냥 지워주는 것으로 해결했으나 문제가 지속될 시 댓글로 알려주시길 바랍니다.
from konlpy.tag import Okt
from collections import Counter
nouns_tagger = Okt()
nouns = nouns_tagger.nouns(texts.content_corpus)
count = Counter(nouns)
# 편의를 위해 한 글자인 키워드 제거하기
remove_char_counter = Counter({x : count[x] for x in count if len(x) > 1})
print(remove_char_counter)
지금까지의 결과를 출력하면 다음과 같습니다.
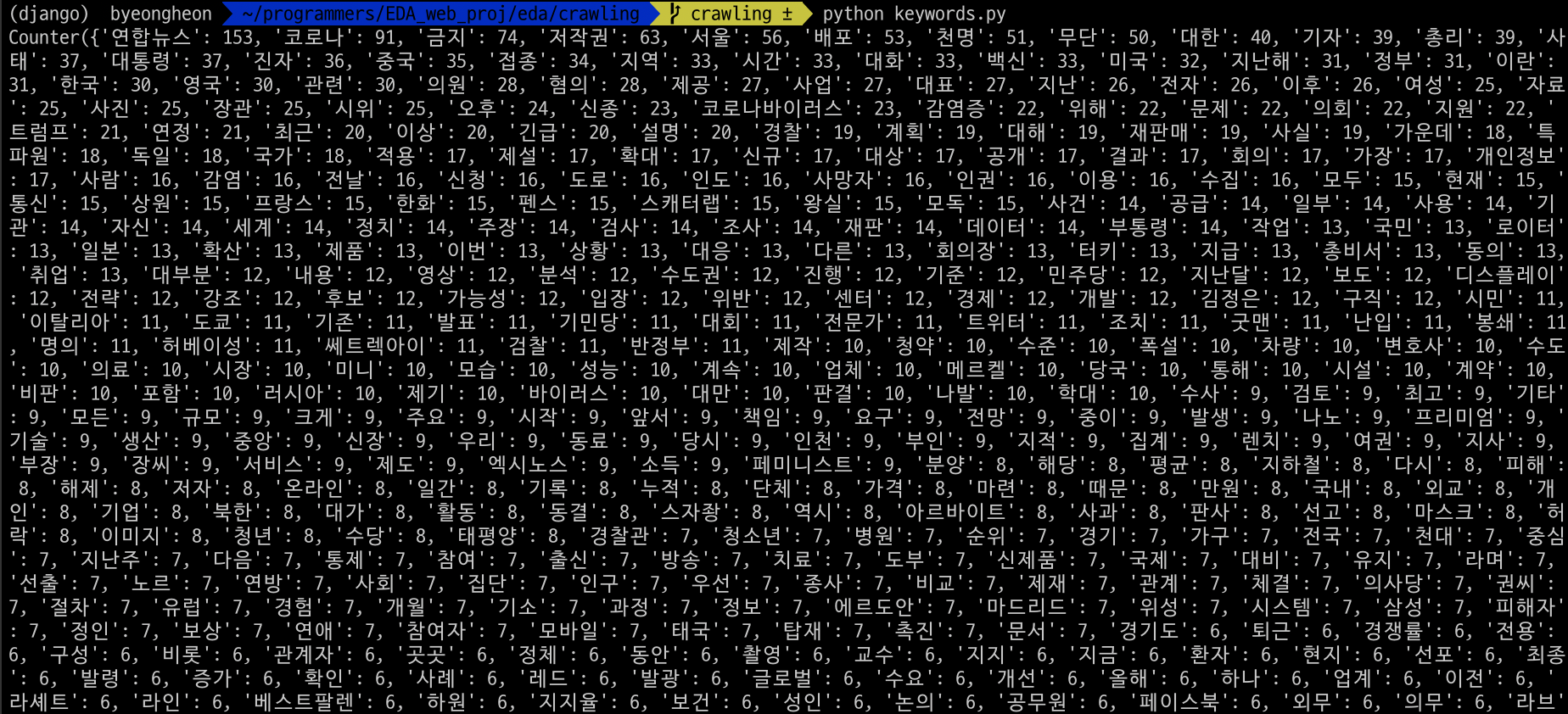
기사 자체의 내용과는 상관 없는 키워드들이 많이 추출된 것을 보실 수 있습니다. 따라서 불용어를 추가해 키워드들을 필터링할 필요가 있습니다.
불용어를 추가하는 방법은 다음과 같습니다.
# 한국어 약식 불용어 사전을 이용해 키워드 가다듬기 (https://www.ranks.nl/stopwords/korean)
korean_stopwords_path = "./data/korean_stopwords.txt"
with open(korean_stopwords_path, encoding='utf8') as f:
stopwords = f.readlines()
stopwords = [x.strip() for x in stopwords]
# 문서의 특징에 따른 불용어를 추가하기
namu_news_stopwords = ['연합뉴스', '저작권', '배포', '무단', '제공', '금지', '기자', '특파원', '사진', '시간', '지난해', \
'지난', '이후', '관련', '자료', '오후', '이번', '내용', '영상', '대표', '지역', '혐의', '정부', '문제', '대해', '가장', '로이터', '보도']
for stopword in namu_news_stopwords:
stopwords.append(stopword)
# 키워드 데이터에서 불용어를 제거하기
remove_char_counter = Counter({x : remove_char_counter[x] for x in count if x not in stopwords})
print(remove_char_counter)
워드 클라우드
지금까지 분석한 키워드를 시각화합니다. pytagcloud 패키지를 통해 시각화를 진행해보도록 하겠습니다. 다음 패키지들을 설치해 주시길 바랍니다.
import random
import pytagcloud
import webbrowser
# 상위 40개의 키워드를 추출합니다.
ranked_tags = remove_char_counter.most_common(40)
# 추출한 키워드를 워드클라우드 이미지로 만들어 줍니다.
taglist = pytagcloud.make_tags(ranked_tags, maxsize=80)
pytagcloud.create_tag_image(taglist, 'wordcloud.jpg', size=(900, 600), fontname='NanumBarunGothic', rectangular = False)
결과는 다음과 같습니다.

<참고문헌>
https://www.youtube.com/watch?app=desktop&v=cPhUKnLGoGw&list=PLVsNizTWUw7FmLj3IMECoauQ_-DUbNF0M&index=10&t=0s
https://i-am-eden.tistory.com/9
댓글남기기